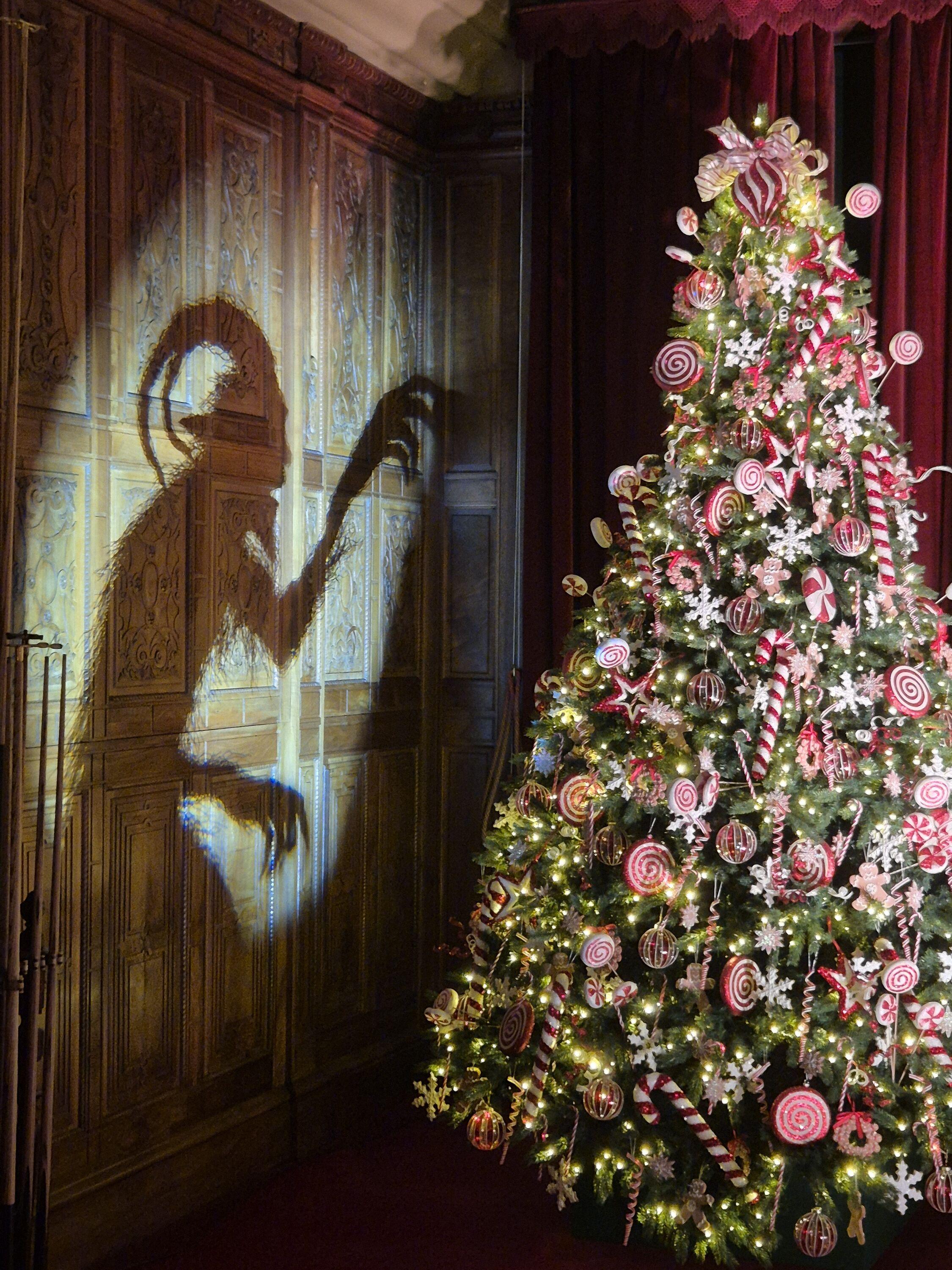Return to Neverbury
Somewhere on the coast of England, Neverbury is a little quaint seaside town with the kind of problems that a lot of quaint little English seaside towns have these days... magicians, lawyers, creeping horrors, changelings, folk music purists, portals to hell, idle gods, ghosts, militant amateur cycling clubs, and a serious problem with something called "Big Chicken".
.jpg)
Havoc Files 6
Take a trip down memory lane with eight new stories from Candy Jar’s Doctor Who spin-off ranges.

Welcome to Neverbury
Somewhere on the coast of England, Neverbury is a quaint little seaside town with the kind of problems that a lot of quaint little English seaside towns have these days... demons, serial killers, immortals, thieves, time travellers, ghosts, vampires, haunted houses, witches, an extraordinarily strident village council, and monsters.